

I have too many tools, said no woodworker ever!
Lisa Stronzi
This article will share the tools used by Data Scientists in our daily work, and explore how they can also be helpful for other teams. Because Python is where we do most of our work, the tools we are using are also mainly collections of Python libraries.
What does a Data Scientist do?
- Data Acquisition and Exploration
- Model Development
- Model Deployment
- Monitoring
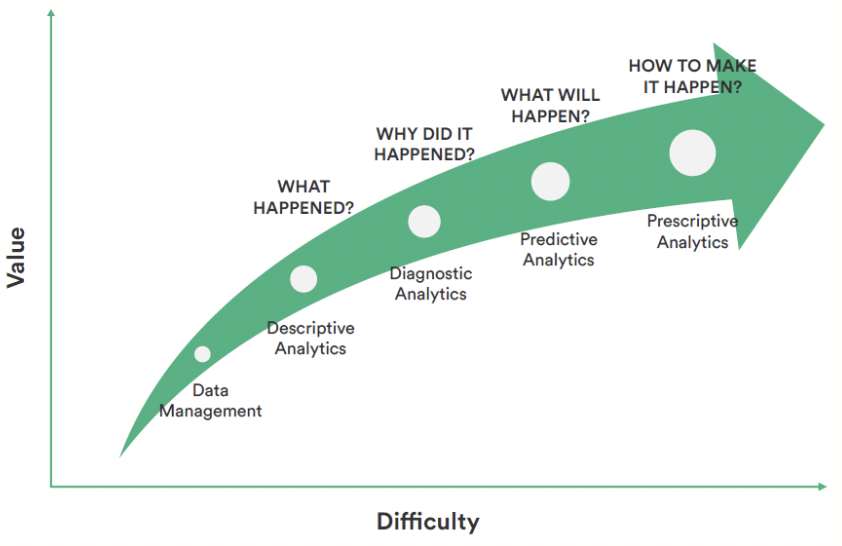
We will share some of the tools for the first 2 steps (Data Acquisition and Exploration, and Model Development) in this article.
How to get these tasks done efficiently?
Below are the tools in python to help us work efficiently with a variety of customisation
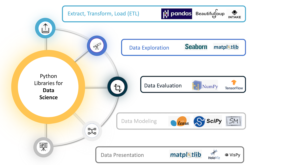
Before sharing about Python and its libraries, we will first go through SQL and its use for analysis and predictive modelling.
SQL
- SQL is a standard language for storing, manipulating and retrieving data in databases. SQL can be used in database systems like MySQL, SQL Server, MS Access, Postgres, as well as data warehouse systems like BigQuery and Redshift.
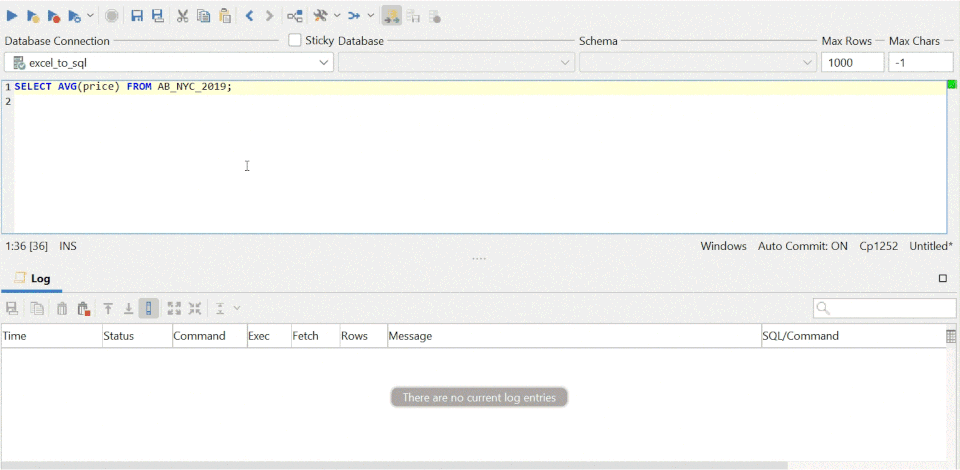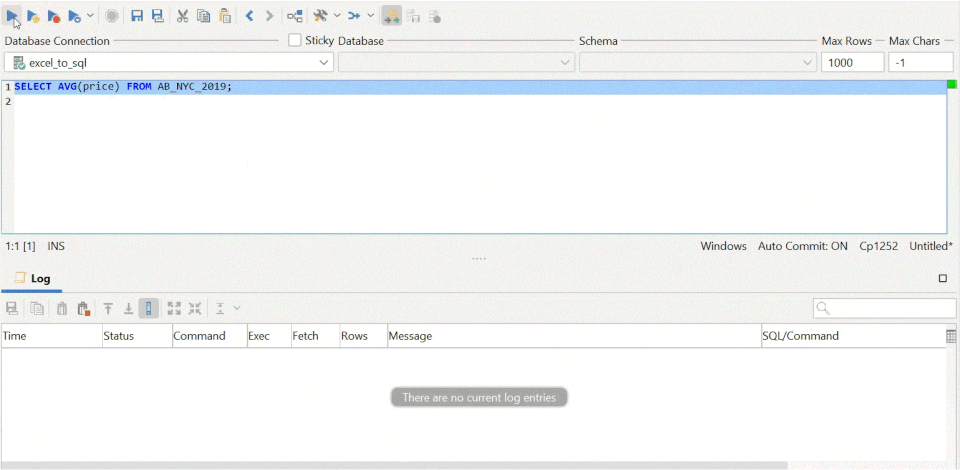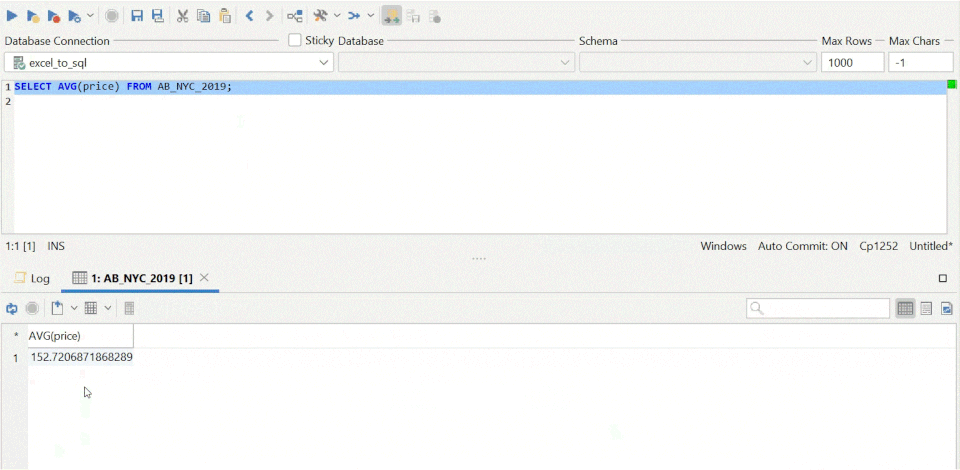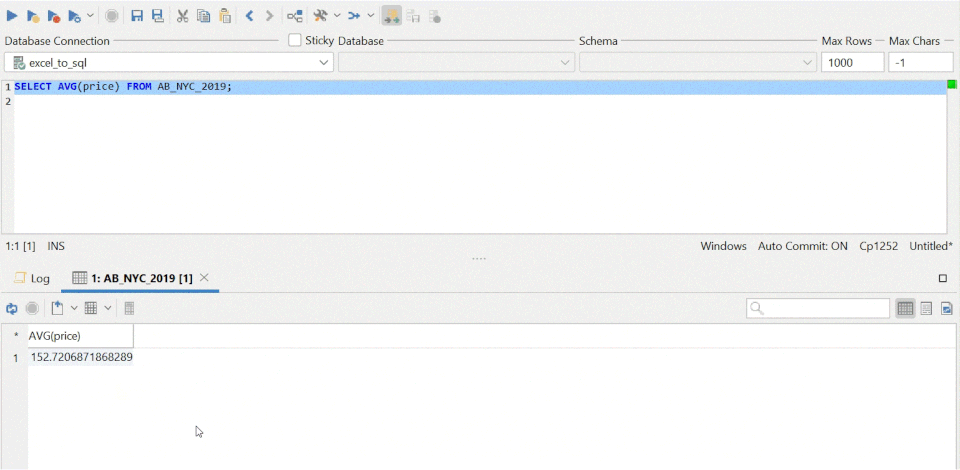
- The skills necessary to be a good data scientist include being able to retrieve and work with data, and to do that we need to be well versed in SQL, the standard language for communicating with database systems. Every organisation has a database and to read and retrieve data from it for data modelling, we use SQL either by querying using python, directly or other means.
General Tools
About Python and its libraries
jupyter notebook
- The name, “jupyter”, comes from the core supported programming languages that it supports: Julia, Python, and R and “notebook” denotes a document that contains both code and rich text elements. Because of the mix of 2, it’s a great place to bring the interactive analysis code and outcome in one place.
How to install jupyter notebook
- Using Anaconda: Install Python and Jupyter using the Anaconda Distribution, which includes Python, the Jupyter Notebook, and other commonly used packages for scientific computing and data science.
- Using PIP: Install Jupyter using the PIP package manager used to install and manage software packages/libraries written in Python. – When using
Jupyter, we can choose to execute individual cells rather than run the whole script all at once.
You will see a few examples of jupyter notebooks for libraries mentioned below.
For more details you can go to jupyter.org
Data Acquisition and Exploration
Jupyter Notebook for Data Exploration
- One of the reason why Jupyter Notebook is often used is that we can run step by step codes and see the outcome, as well as to visualise the data. In this way, it helps us in the early phases of the project, especially when exploring data and when initially developing the model.
Import pandas as pd
pandasis one of the first libraries we use when we want to load the data. It creates a 2-dimension tabular data structure (called as DataFrame inpandas) from the database and interfaces with data using DataFrames, which have named columns for data manipulation. It is similar to a spreadsheet, a SQL table or the data.frame in R.
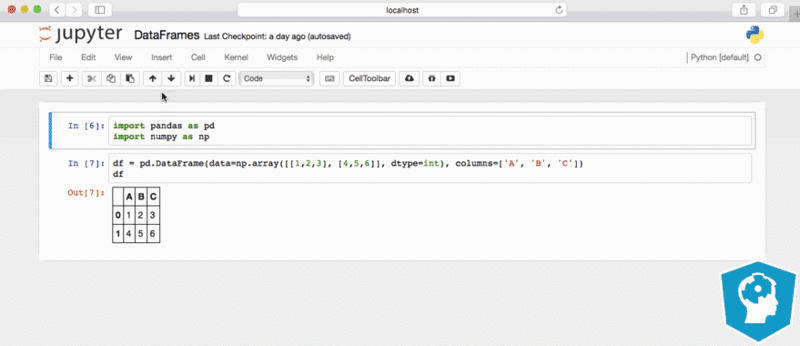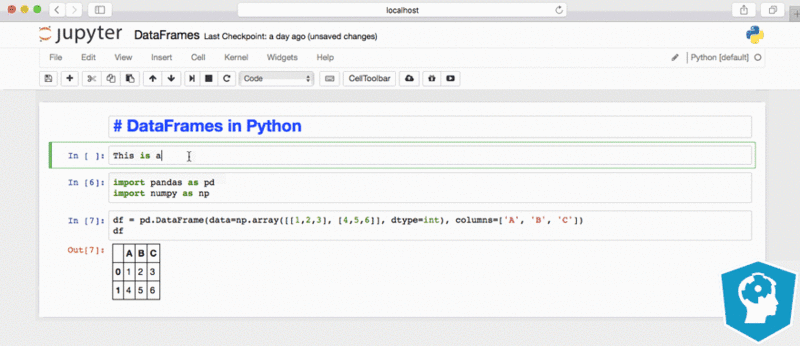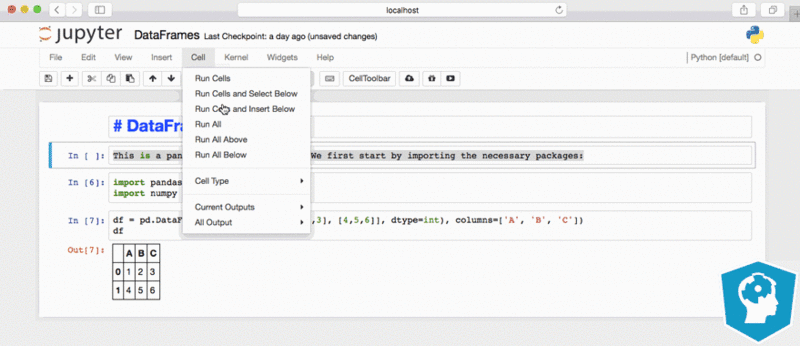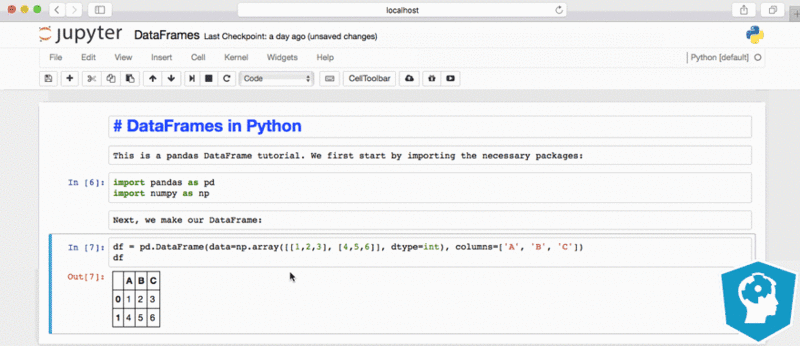
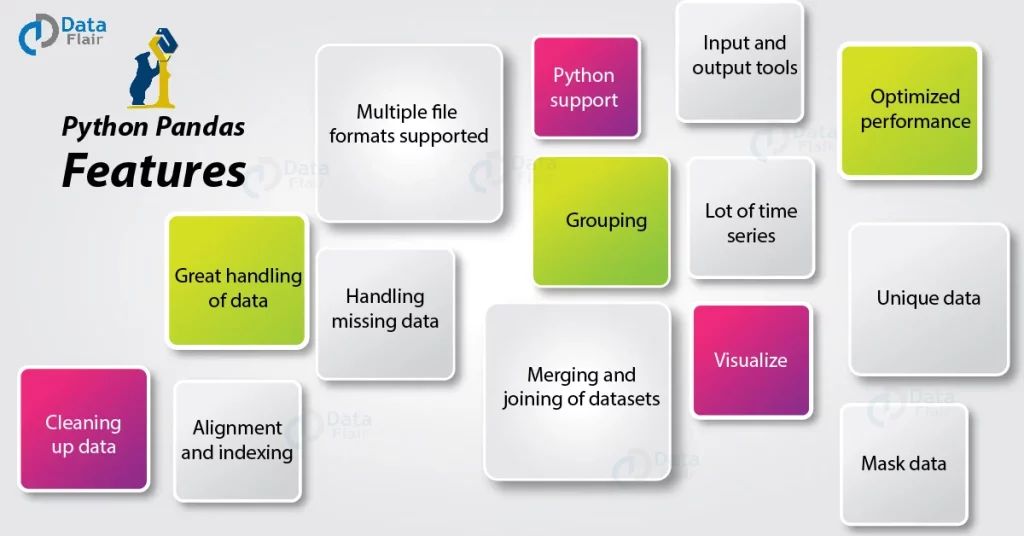
pandas make it easier to explore and manipulate data by providing different features mentioned in image.
💡 pandas is preferred over multiple other tools like SQL, R, etc.. because it is faster and easier to perform data analyses for given DataFrame/Series.
Import NumPy as np
While pandas helps us manipulate and analyze data in tabular format, NumPy helps us
- To provide various method/function for Array, Metrics, and linear algebra.
- It stands for Numerical Python and provides lots of useful features for operations on n-arrays and matrices in Python.
- This library provides vectorisation of mathematical operations on the
NumPyarray type, which enhances performance and speeds up the execution. - It’s very easy to work with large multidimensional arrays and matrices using
NumPy.
A small example of data handling using numpy
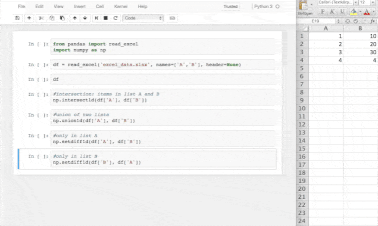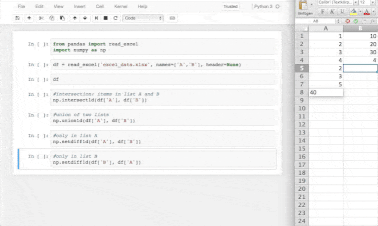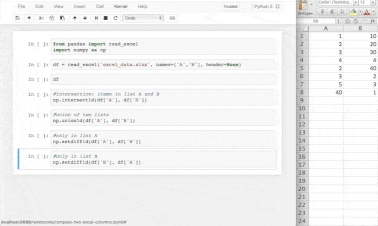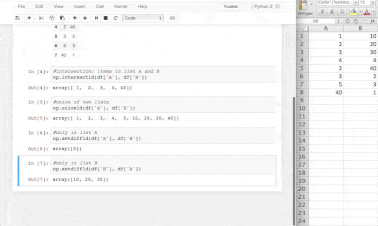
💡pandasvsNumPy- NumPy performs better than pandas when it comes to complex mathematical calculations on multidimensional arrays with data lesser than 50k rows. We often use both tools when manipulating and exploring data
Data Visualisation
import matplotlib.pyplot as plt
One important part of storytelling through data is “Correct visualisation”.
There are multiple libraries in python which helps us draw plots with an option to customise and save the image. matplotlib is one of them!
matplotlib is a collection of command style functions that make matplotlib work like MATLAB.
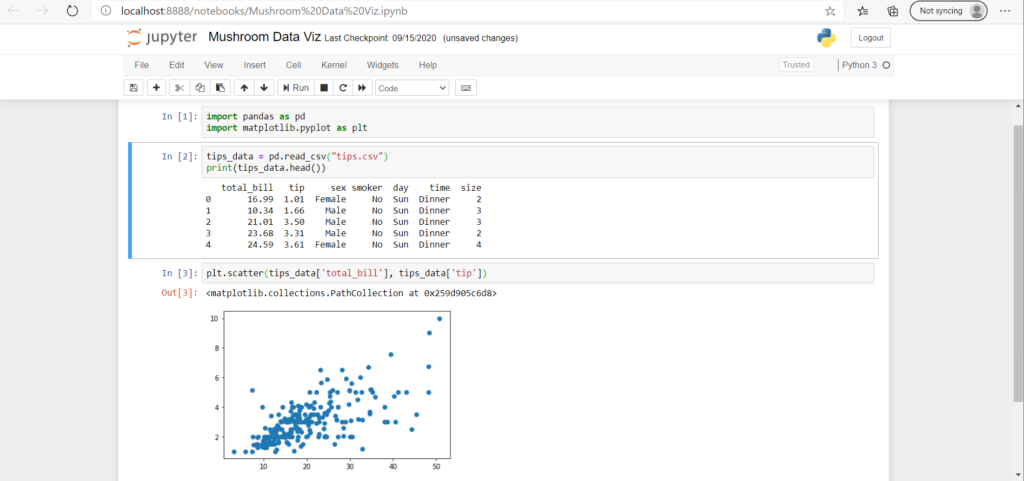
💡matplotlibworks efficiently with DataFrames and arrays. There are other libraries likeseaborn,plotlywhich are equally used for interactive and customizable plots, and often provide better looking graphs
Model Development
import scikit-learn as sklearn
There are multiple open source and paid tools available for predictive analytics, one of which is scikit-learn library used by many Data Scientists to build ML models since it is:
- Simple and efficient tools for predictive data analysis
- Accessible to everybody, and reusable in various contexts
- Built on
numpy,scipy, andmatplotlib - Open source, commercially usable – BSD license
sklearn provides access to high-quality, easy-to-use, implementations of popular algorithms so scikit-learn is a great place to start.
Example of logistic regression model in sklearn

While sklearn provides a large library of model types, data scientists also make frequent use of other packages, especially if they are creating more specialised types of machine learning models. For example, there are libraries for creating tree-based models which have better performance especially when training with large amount of data, such as CatBoost and XGBoost. Neural network models, which are also very popular especially for natural language processing and computer vision models, are commonly built using Tensorflow or PyTorch .
Examples of packages for tree-based models
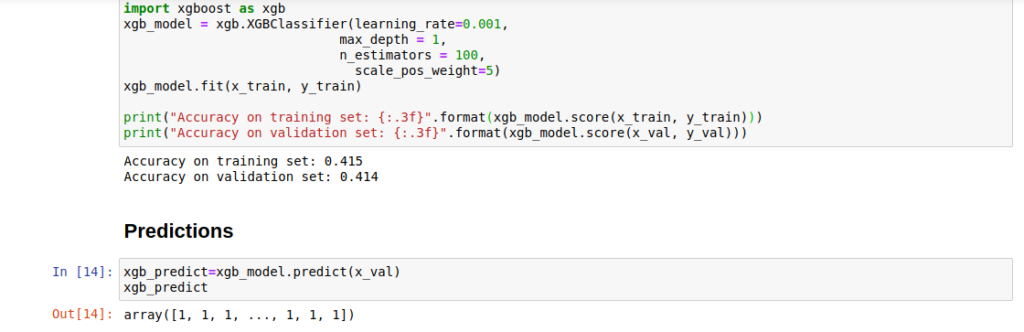
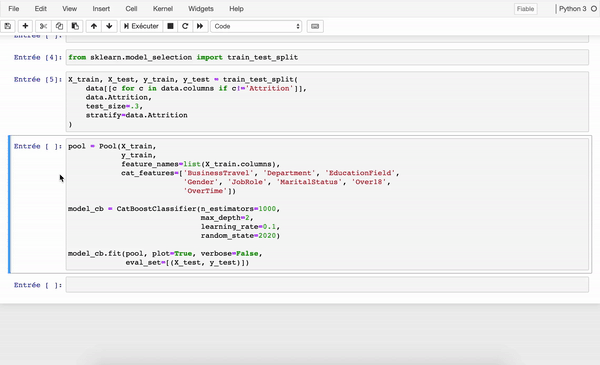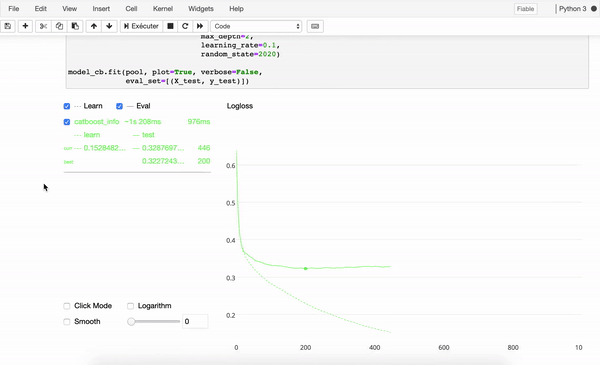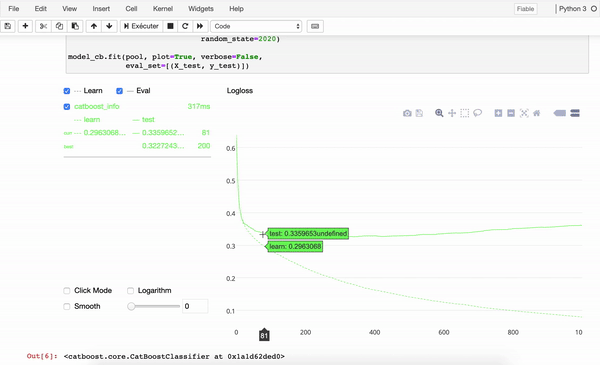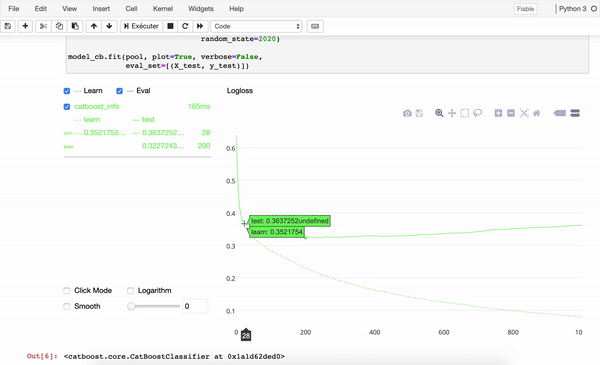
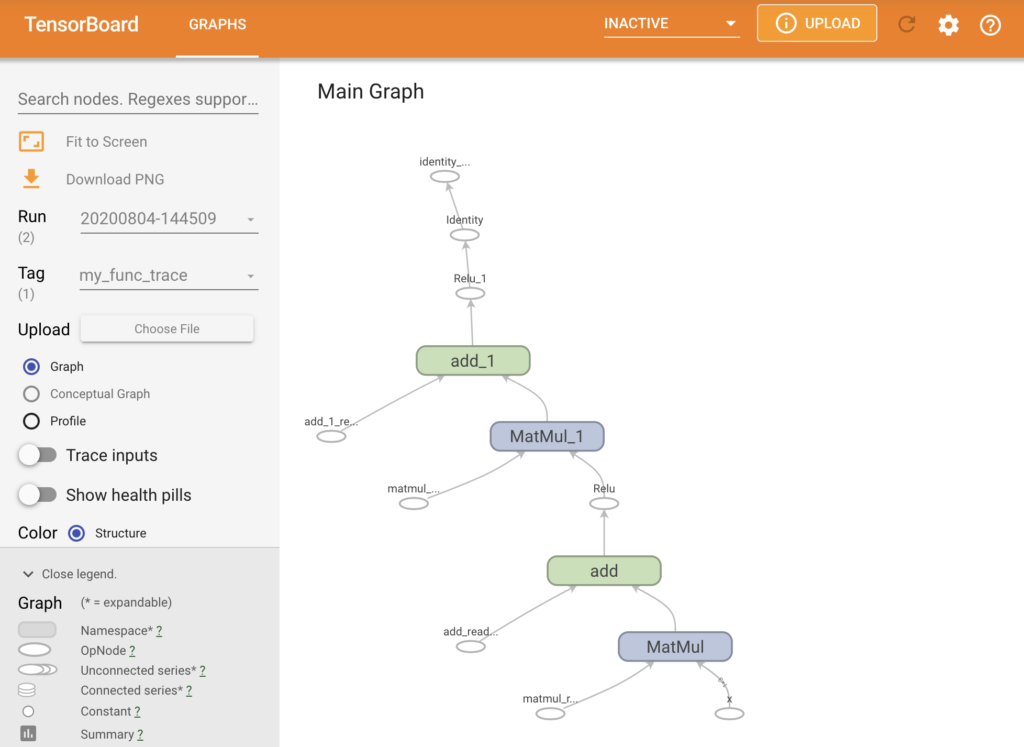
Examples of neural network model packages
Neural network model built in Tensorflow and visualised using Tensorboard
💡 sklearn is one of the most commonly used library and provides a good baseline for learning machine learning and experimenting with many basic models.
Conclusion
Python libraries are preferred by data teams as it is easier and faster to perform data analytics tasks all in one place. Especially, for people who prefer MS Excel, they can easily switch to these python libraries to fast track their work when there is big data involved or otherwise too.
You can refer to below documents for the libraries
- pandas – to analyze DataFrame
- numpy – to compute numerical operations on multidimensional array
- matplotlib – to visualize data
- scikit-learn – to conduct predictive analytics
Written by Mitali Chotrani
If you are passionate about data and want to be involved in making the future of finance accessible to businesses of all scales, let’s be part of our team. Find out more about our available vacancy on this link.



